11Die Mechanik der Vorhersage: Forward-Propagation
Nachdem die grundlegende Struktur neuronaler Netzwerke eingeführt wurde, wenden wir uns nun der Frage zu, wie Informationen konkret durch ein solches Netzwerk verarbeitet werden. Dieser Prozess – die Forward-Propagation – beschreibt den Weg der Daten von der Eingabe bis zur Ausgabe des Modells.
Ziel dieses Kapitels ist es, diesen Ablauf schrittweise zu formalisieren: von einzelnen Rechenoperationen über eine ganze Schicht bis hin zur kompakten Matrixdarstellung.
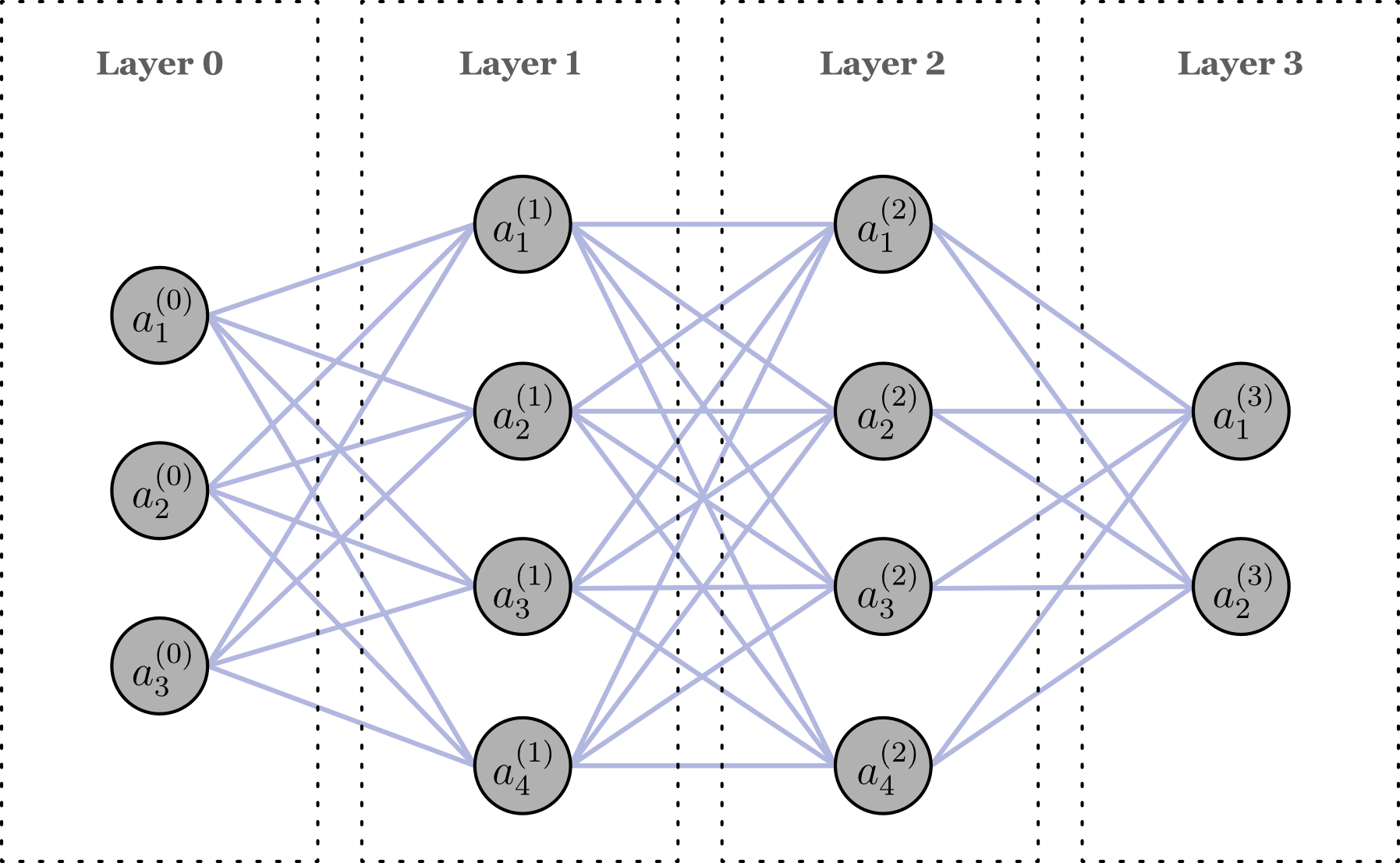
11.1 Einheitliche Notation für Schichten und Neuronen
Zur Beschreibung neuronaler Netzwerke verwenden wir eine einheitliche Notation, die es erlaubt, auch komplexe Architekturen übersichtlich darzustellen.
Der Ausgabewert eines Neurons wird als Aktivierung bezeichnet und mit
\[
a^{(l)}_i
\]
notiert. Dabei bezeichnet \(l\) die Schichtnummer und \(i\) den Index des Neurons innerhalb dieser Schicht.
Die Eingabedaten selbst werden als Aktivierungen der Schicht \(l = 0\) aufgefasst:
\[
\mathbf{a}^{(0)} = \text{Input-Layer}
\]
Diese Konvention erlaubt es, alle folgenden Berechnungen in derselben Form zu formulieren.
11.1.1 Gewichte und Richtung der Information
Ein einzelnes Gewicht wird notiert als
\[
W^{(l)}_{i,j}
\]
Dabei gilt:
\(l\) bezeichnet die Zielschicht,
\(i\) den Index des empfangenden Neurons,
\(j\) den Index des sendenden Neurons der vorherigen Schicht.
Diese Wahl der Indizes ist so getroffen, dass sich die Berechnung einer Schicht später direkt als Matrixmultiplikation schreiben lässt. Zusätzlich besitzt jedes Neuron einen Bias-Term \(b^{(l)}_i\).
11.2 Berechnung innerhalb eines Neurons
Für ein beliebiges Neuron \(i\) in Schicht \(l\) ergibt sich der Netzeingang als
Der Netzeingang \(z^{(l)}_i\) eines Neurons bezeichnet die gewichtete Summe aller eingehenden Signale aus der vorherigen Schicht, bevor eine Aktivierungsfunktion angewendet wird. Auf diesen Netzeingang wird eine Aktivierungsfunktion \(f\) angewendet:
\[
a^{(l)}_i = f\left(z^{(l)}_i\right)
\]
Diese beiden Schritte – lineare Kombination und nichtlineare Aktivierung – bilden das elementare Rechenmuster aller Feedforward-Netzwerke.
11.3 Explizite Berechnung einer Schicht
Bevor wir zur kompakten Matrixschreibweise übergehen, betrachten wir die Berechnung einer Schicht explizit anhand einzelner Gleichungen. Wir betrachten den Übergang von der Eingabeschicht zur ersten verborgenen Schicht.
Für die Netzeingänge dieser Neuronen ergeben sich:
Alle vier Gleichungen besitzen dieselbe Struktur. Sie unterscheiden sich lediglich in den verwendeten Gewichten und Bias-Termen. Diese Regularität ist der entscheidende Hinweis darauf, dass sich die Berechnung einer gesamten Schicht zusammenfassen lässt.
11.4 Vektor- und Matrixdarstellung
Wir überführen obiges Beispiel in die Matrix-Schreibweise. Hierfür definieren wir die Aktivierungen der vorangegangenen Schicht, die Netzeingänge sowie die Bias-Werte als Vektoren:
Zusätzlich benötigen wir die Gewichtsmatrix\(W^{(1)}\). Sie ordnet die Gewichte so an, dass jede Zeile genau die Verbindungen enthält, die zu einem bestimmten empfangenden Neuron führen:
Diese kompakte Vektorgleichung ersetzt die unübersichtliche Menge an Einzelberechnungen durch eine einzige, präzise mathematische Operation. Sie liefert exakt dieselben Ergebnisse wie die zuvor explizit aufgeschlüsselten Gleichungen.
11.5 Allgemeine Schichtberechnung in Matrixform
Da alle Neuronen einer Schicht nach demselben Muster berechnet werden, lassen sich die Einzelausdrücke für jede beliebige Schicht \(l\) verallgemeinern. Die Gewichtsmatrix einer Schicht ist definiert als:
\[
W^{(l)} \in \mathbb{R}^{n_l \times n_{l-1}}
\]
Unter Verwendung der Vektorschreibweise ergibt sich die vollständige Forward-Propagation einer Schicht zu:
In dieser Darstellung entspricht jede Zeile der Gewichtsmatrix genau einem Neuron der Schicht \(l\) – exakt der Struktur, die zuvor in den Einzelgleichungen sichtbar war.
11.6 Rechnerische Umsetzung und Hardware-Aspekte
Die Forward-Propagation besteht im Wesentlichen aus großen Matrixmultiplikationen. Diese lassen sich stark parallelisieren und sind daher besonders gut für Grafikprozessoren (GPUs) und spezialisierte KI-Beschleuniger geeignet.
In der Praxis sind weniger die Rechenoperationen selbst als vielmehr Speicherbedarf und Speicherbandbreite limitierende Faktoren. Die mathematische Struktur der Forward-Propagation bestimmt somit unmittelbar die Anforderungen an die zugrunde liegende Hardware.
11.6.1 Beispiel (Python-Code):
Code
import numpy as np# 1. Aktivierungsfunktion definieren (Beispiel: Sigmoid)def sigmoid(z):return1/ (1+ np.exp(-z))# 2. Eingangsdaten (a0) als Vektor (3 Eingänge)# Entspricht a_0_1, a_0_2, a_0_3a0 = np.array([0.5, 1.2, -0.2])# 3. Gewichtsmatrix W1 (4 Neuronen x 3 Eingänge)# Jede Zeile enthält die Gewichte für ein empfangendes NeuronW1 = np.array([ [0.1, 0.2, 0.3], # Gewichte für Neuron 1 [0.4, 0.5, 0.6], # Gewichte für Neuron 2 [0.7, 0.8, 0.9], # Gewichte für Neuron 3 [1.0, 1.1, 1.2] # Gewichte für Neuron 4])# 4. Bias-Vektor b1 (4 Neuronen)b1 = np.array([0.1, 0.1, 0.1, 0.1])# --- FORWARD PROPAGATION SCHRITT ---# Lineare Kombination: z = W * a + bz1 = np.dot(W1, a0) + b1# Nichtlineare Aktivierung: a = f(z)a1 = sigmoid(z1)print("Netzeingang (z1):", z1)print("Aktivierung (a1):", a1)
11.7 Ausblick
Mit der Forward-Propagation können aus gegebenen Gewichten Vorhersagen erzeugt werden. Die zentrale offene Frage lautet nun, wie diese Gewichte so angepasst werden, dass das Netzwerk bessere Ergebnisse liefert.
Dies ist Gegenstand des nächsten Kapitels, in dem wir den Lernmechanismus neuronaler Netzwerke – die Backpropagation – untersuchen.